Ashwini PokleI am a Research Scientist at Google. I completed my PhD from the Machine Learning Department at Carnegie Mellon University where I was fortunate to be advised by Prof. Zico Kolter. My thesis title was "Deep Equilibrium Models and Diffusion Models in Practice: Methods for improving efficiency". Prior to my PhD, I completed my Master's in Computer Science from Stanford University. During my Master's, I also worked as a Research Assistant at Stanford Vision and Learning Lab (SVL) under supervision of Prof. Silvio Savarese. Prior to joining Stanford, I worked as a Software Development Engineer at Amazon where I was a part of the Prime Video team and Fulfillment Center Technologies team. I received my Bachelor’s in Computer Science from Birla Institute of Technology and Science, Pilani, India. I have also spent a summer at USC Melady lab where I worked with Prof. Yan Liu. I have previously interned at FAIR (Meta AI) and Bosch AI. Email / GitHub / Google Scholar / LinkedIn |

|
ResearchI am broadly interested in generative models (diffusion models, flows etc.) and deep equilibrium models (DEQs). |
|
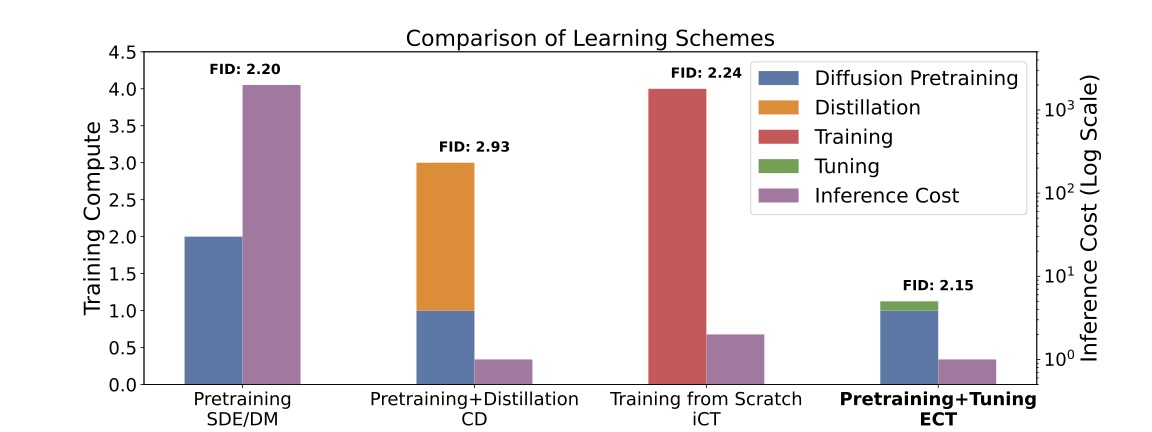
Consistency Models Made EasyZhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, and Zico Kolter ICLR, 2025 arxiv | code We propose an alternative scheme for training Consistency Models (CM), vastly improving the efficiency of building such models. We express CM trajectories via a particular differential equation and argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. |

|
Training-free Linear Image Inverses via FlowsAshwini Pokle, Matthew J. Muckley, Ricky T. Q. Chen, Brian Karrer Transactions on Machine Learning Research (TMLR), 2024 arxiv | We propose a training-free method to solve linear inverse problems using pretrained flow models. Our experiments indicate that images restored via a conditional Optimal transport path, a specific parametrization of flows, are perceptually superior compared to those restored via diffusion paths. |

|
Deep Equilibrium Based Neural Operators for Steady-State PDEsTanya Marwah*, Ashwini Pokle*, J. Zico Kolter, Zachary Chase Lipton, Jianfeng Lu and Andrej Risteski Advances in Neural Information Processing Systems (NeurIPS), 2023 arxiv | code We demonstrate the benefits of weight-tying as an effective architectural choice for neural operators when applied to steady-state PDEs. We propose FNO-DEQ, a deep equilibrium model based architecture for solving steady-state PDEs that outperforms non-weight tied baselines with 4-6x parameters. |
|
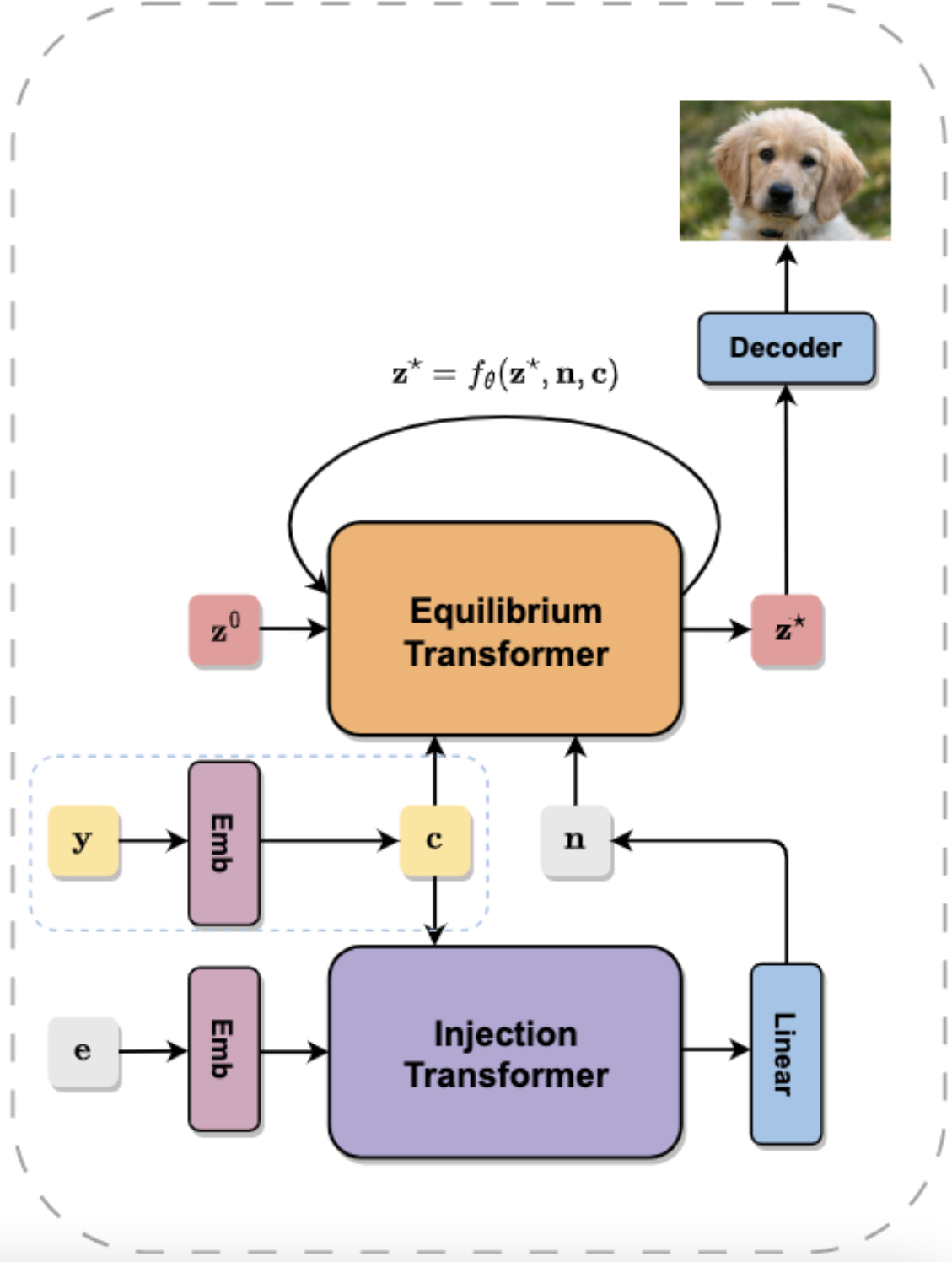
One-Step Diffusion Distillation via Deep Equilibrium ModelsZhengyang Geng*, Ashwini Pokle*, and J. Zico Kolter Advances in Neural Information Processing Systems (NeurIPS), 2023. An earlier version of this work was also presented at Deployable Generative AI workshop, ICML, 2023 arxiv | code We propose Generative Equilibrium Transformer (GET), a deep equilibrium model-based variant of Vision Transformer that can efficiently distill sampling chain of diffusion models (EDM) into a single-step generative model. |
|
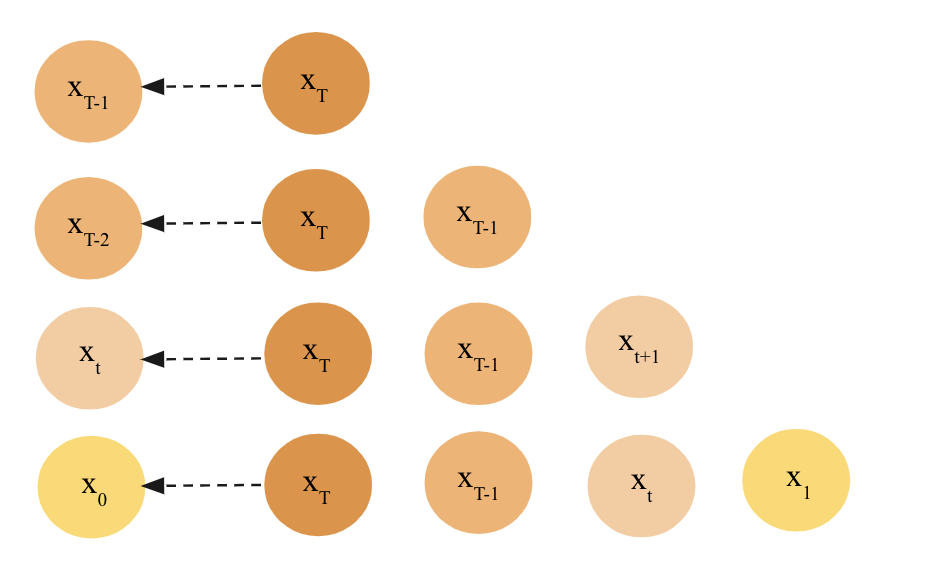
Deep Equilibrium Approaches to Diffusion ModelsAshwini Pokle, Zhengyang Geng, and J. Zico Kolter Advances in Neural Information Processing Systems (NeurIPS), 2022 arxiv | code We write the sampling process of DDIM as a deep equilibrium model. This allows us to do fast parallel sampling of DDIM by batching the workload, and enables use of memory efficient O(1) implicit gradients to backprop through the diffusion chain. |
|
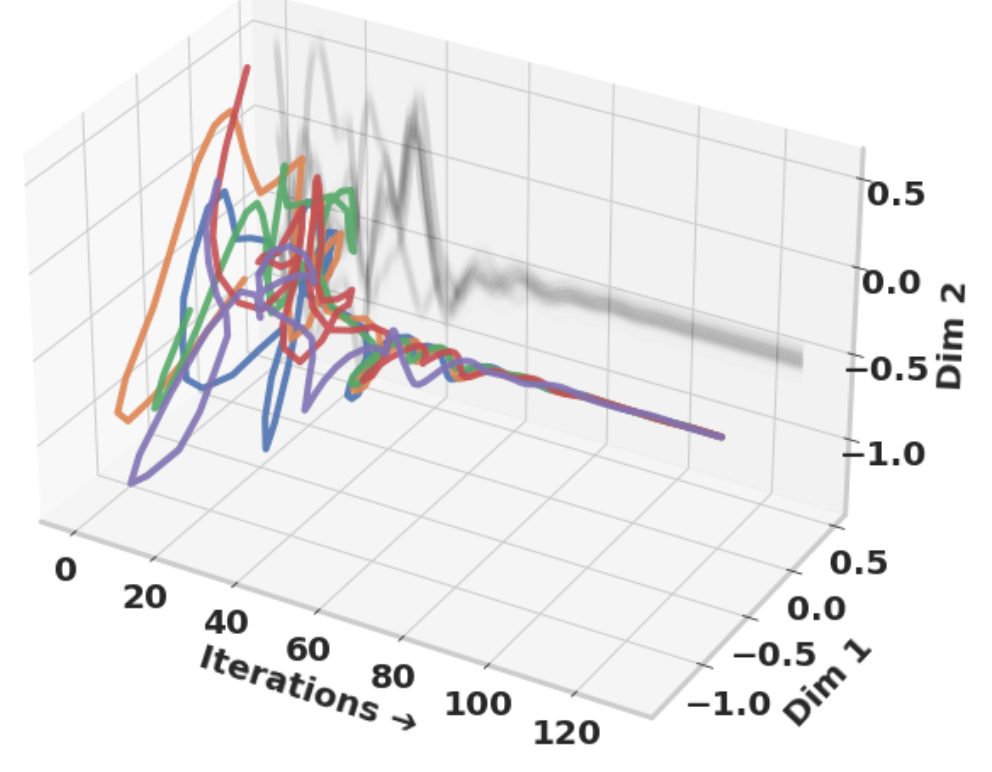
Path independent equilibrium models can better exploit test-time computationCem Anil*, Ashwini Pokle*, Kaiqu Liang*, Johannes Treutlein, Yuhuai Wu, Shaojie Bai, J. Zico Kolter, and Roger Baker Grosse Advances in Neural Information Processing Systems (NeurIPS), 2022 arxiv | We show that equilibrium models display strong upwards generalization on hard algorithmic tasks when these models converge to the same steady-state behaviour regardless of initialization, a phenomenon we term as “path independence”. |
|
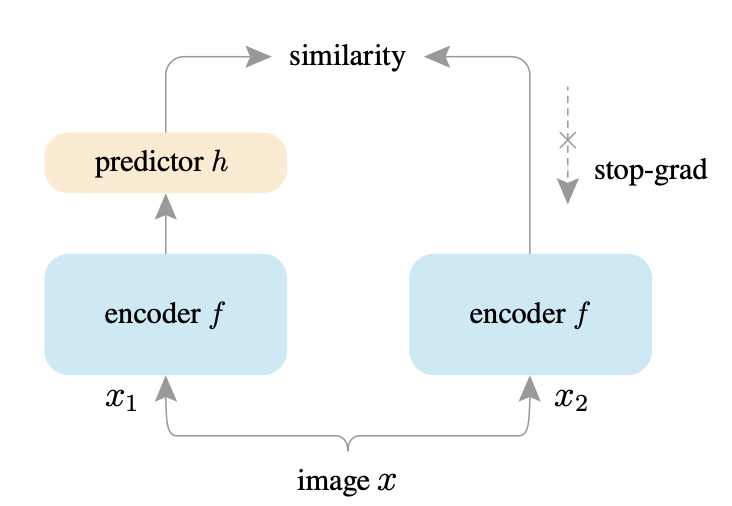
Contrasting the Landscape of contrastive and non-contrastive learningAshwini Pokle*, Jinjin Tian*, Yuchen Li* and Andrej Risteski Conference on Artificial Intelligence and Statistics (AISTATS), 2022 arxiv | code We show through theoretical results and controlled experiments on simple data models that non-contrastive losses have a preponderance of non-collapsed bad minima. Moreover, we show that the training process does not avoid these minima. |

|
Visually-Grounded Library of Behaviors for Generalizing Manipulation Across Objects, Configurations and ViewsHsiao-Yu Tung*, Jingyun Yang*, Yunchu Zhang*, Gaurav Pathak, Ashwini Pokle, Christopher G. Atkeson, and Katerina Fragkiadaki Conference on Robot Learning (CoRL), 2021 arxiv | code We propose a method for manipulating diverse objects across a wide range of initial and goal configurations and camera placements. We disentangle the standard image-to-action mapping into two separate modules: (1) a behavior selector which selects the behaviors that can successfully perform the desired tasks on the object in hand, and (2) a library of behaviors each of which conditions on extrinsic and abstract object properties to predict actions to execute over time. |

|
Deep Local Trajectory Planning and Control for Robot NavigationAshwini Pokle, Roberto Martín-Martín, Patrick Goebel, Vincent Chow, Hans M. Ewald, Junwei Yang, Zhenkai Wang, Amir Sadeghian, Dorsa Sadigh, Silvio Savarese, and Marynel Vázquez IEEE International Conference on Robotics and Automation (ICRA), 2019 arxiv | We proposed a navigation system that combines ideas from hierarchical planning and machine learning. The system uses a traditional global planner to compute optimal paths towards a goal, and a deep local trajectory planner and velocity controller to compute motion commands. |
|
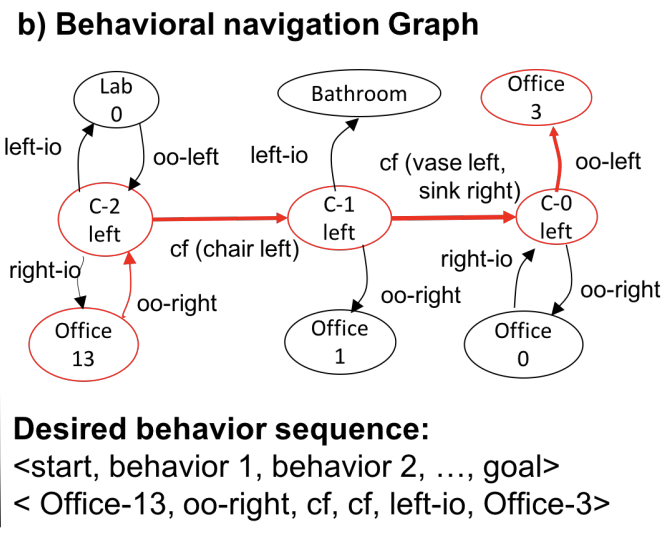
Translating Navigation Instructions in Natural Language to a High-Level Plan for Behavioral Robot NavigationXiaoxue Zang*, Ashwini Pokle*, Marynel Vázquez, Kevin Chen, Juan Carlos Niebles, Alvaro Soto and Silvio Savarese Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018 arxiv | code We propose an end-to-end deep learning model for translating free-form natural language instructions to a high-level plan for behavioral robot navigation. The proposed model uses attention mechanisms to connect information from user instructions with a topological representation of the environment. |
|
Design and source code from Leonid Keselman's fork of Jon Barron's website |